비전공자의 AI 부트캠프 일지 #9
딥러닝 실습하기
부제 : 딥러닝으로 무엇을 할 수 있을까?
오늘의 주제는?
지난 포스팅에서는 딥러닝의 기초 개념과 원리에 대해서 정리해 봤다. 오늘 포스팅에서는 딥러닝에 필요한 환경과 어떤 것들을 할 수 있는지 정리하고 기록해 보려고 한다.

사실 그동안은 이론 수업이나 코드 실습을 따라가는 과정이 익숙하지도 않고, '내가 이걸로 뭘 할 수 있지?'라는 막연한 생각이 들 때도 많았다. 그런데 2월, 딥러닝 실습 중에서 순환 신경망(RNN) 모델을 이용해서 주가 예측을 해보는 시간이 있었고, 그때 “이거 내가 재미있어하는 부분이네”라는 것을 인지했었다.
순환 신경망이라는 기술 자체보다는 "이걸로 실제로 뭘 할 수 있을까?”라는 활용 지점이 내가 익숙하게 느끼던 주제(데이터 기반 예측, 마케팅, 사용자 반응 데이터)와 연결되면서 자연스럽게 흥미가 생겼던 것 같다.
딥러닝을 위한 환경 만들기
딥러닝을 처음 시작할 때는 딥러닝의 개념을 이해하기 위해 필요한 수학적인 개념인 경사하강법과 미분에 대해서 배웠다. 그 후에는 딥러닝을 실행할 수 있는 환경을 세팅했는데 이때 필요한 도구가 바로 conda와 pytorch였다. 그리고 그 뒤에 딥러닝 프로세스의 핵심 개념인 최적화 함수, 손실값 최적화, 파라미터에 대해서 배우는 과정이 있었다.
conda는 다양한 라이브러리나 버전을 분리해서 사용할 수 있게 도와주는 가상환경 설정 도구이고 pytorch는 우리가 딥러닝 모델을 만들고 훈련시킬 수 있도록 도와주는 딥러닝 프레임워크이다. 이제 많은 데이터의 처리를 기계가 빠르게 처리할 수 있도록 (순서대로 하기엔 너무 올래 걸리고 시간은 또 비용이니깐) 기계가 이해할 수 있는 숫자 배열 및 행렬로 만들어주는 tensor라는 형태로 변환해주고 속도를 높일 수 있도록 데이터를 batch라는 묶음과 병렬 구조 형태로 만들어서 여러 개를 한 번에 계산하게 만든다.
정리하자면 딥러닝은 많은 데이터를 처리하기 위해서 다른 프로그램들과 충돌되지 않도록 conda를 이용해 안전한 가상환경을 만들고 딥러닝 연산에 필요한 계산법을 pytorch라는 프레임워크에서 연산 기능을 가져온다. 그리고 입력된 데이터를 tensor라는 것으로 기계가(컴퓨터가) 이해할 수 있도록 데이터를 숫자 배열로 바꿔주고 batch라는 단위로 변환된 값을 병렬 및 묶음 구조 형태로 만들어서 빠르게 계산하는 것이다.

이게 바로 딥러닝의 발전 순서였구나
생각해보니깐 지금까지 부트캠프에서 배운 커리큘럼 흐름 자체가 딥러닝 기술의 발전 순서와 거의 같았던 것 같다.
맨 처음엔 딥러닝을 할 수 있는 환경에 대해서 배우고 이후에는 이미지 분류를 위한 기본 신경망인 MNIST부터 시작했고, 성능 향상을 위해 CNN(합성곱 신경망) 구조를 배웠다. 그다음엔 텍스트나 시간 순서가 중요한 데이터를 다루기 위한 RNN과 정보의 양을 얼마나 전달할 것인지 결정하는 LSTM, 인코더와 디코더 개념이 생긴 seq2seq 그리고 최근에는 자연어 처리 구조인 Transformer, BERT까지 실습했다.
즉, 처음엔 ‘이미지 인식’이라는 정적인 데이터 → 시간 흐름이 있는 ‘순차 데이터’ → 문맥을 파악하는 ‘언어 데이터’로 점점 진화해 온 것이다. 이 흐름을 따라가면서 딥러닝이 단순히 이미지를 분류하는 기술이 아니라 텍스트, 음성, 영상, 움직임, 감정 등 거의 모든 종류의 데이터를 다룰 수 있는 확장되는 기술이라는 것을 알게 되었다.
LSTM을 이용해서 주가 예측 실습해 보기
LSTM(Long Shot-Term Memory)은 순환 신경망(RNN)의 한 종류로, 시간 순서가 중요한 데이터를 처리할 때 과거의 중요한 정보를 더 오래 기억할 수 있도록 설계된 딥러닝 모델이다. 쉽게 말해, 시간이 지남에 따라 오래된 데이터를 잊어가는 RNN의 한계를 보완하기 위해서 "이건 중요한 정보야!"라고 판단되는 내용은 오래 기억하게 만들어준 구조이다.
실습에서는 yfinance 라이브러리를 이용해 야후 파이낸싱에서 제공하는 주가 데이터를 불러왔고 주가 예측에 필요한 컬럼(종가, 시가, 고가 등)을 선택해 준다. 그다음, 기계가 쉽게 이해할 수 있도록 큰 숫자를 작은 숫자로 조정해 주는 스케일링이라는 정규화 작업을 진행한다. 이제 데이터를 이전 7일간의 데이터를 기반으로 다음 날 주가를 예측할 수 있는 형태로 재구성했고, 이를 tensor로 딥러닝 모델 학습에 맞는 형태로 변환해서 데이터 셋을 준비한다.

이다음에는 딥러닝 모델 학습을 위해서 torch 프레임워크를 활용해 LSTM 구조의 모델을 불러와서 레이어 구조를 조정해 모델을 설계한다. 학습 속도를 높이기 위해서 이 설계된 모델을 GPU환경(cuda)으로 보내주고 이후 몇 번 학습할지, 어떤 최적화 함수(adam)를 쓸지 등 하이퍼 파라미터를 설정한다. 그리고 이 모델을 학습시킨다. 가장 중요한 것은 잘 학습된 것이 맞나? 인 것인데 학습한 이후에는 새로운 데이터를 입력해 예측값을 출력하고, 실제 값과 예측 값이 얼마나 차이 나는지 비교(평가)하는 그래프를 그려봄으로써 이 모델이 잘 학습되었다는 것까지 확인할 수 있었다.
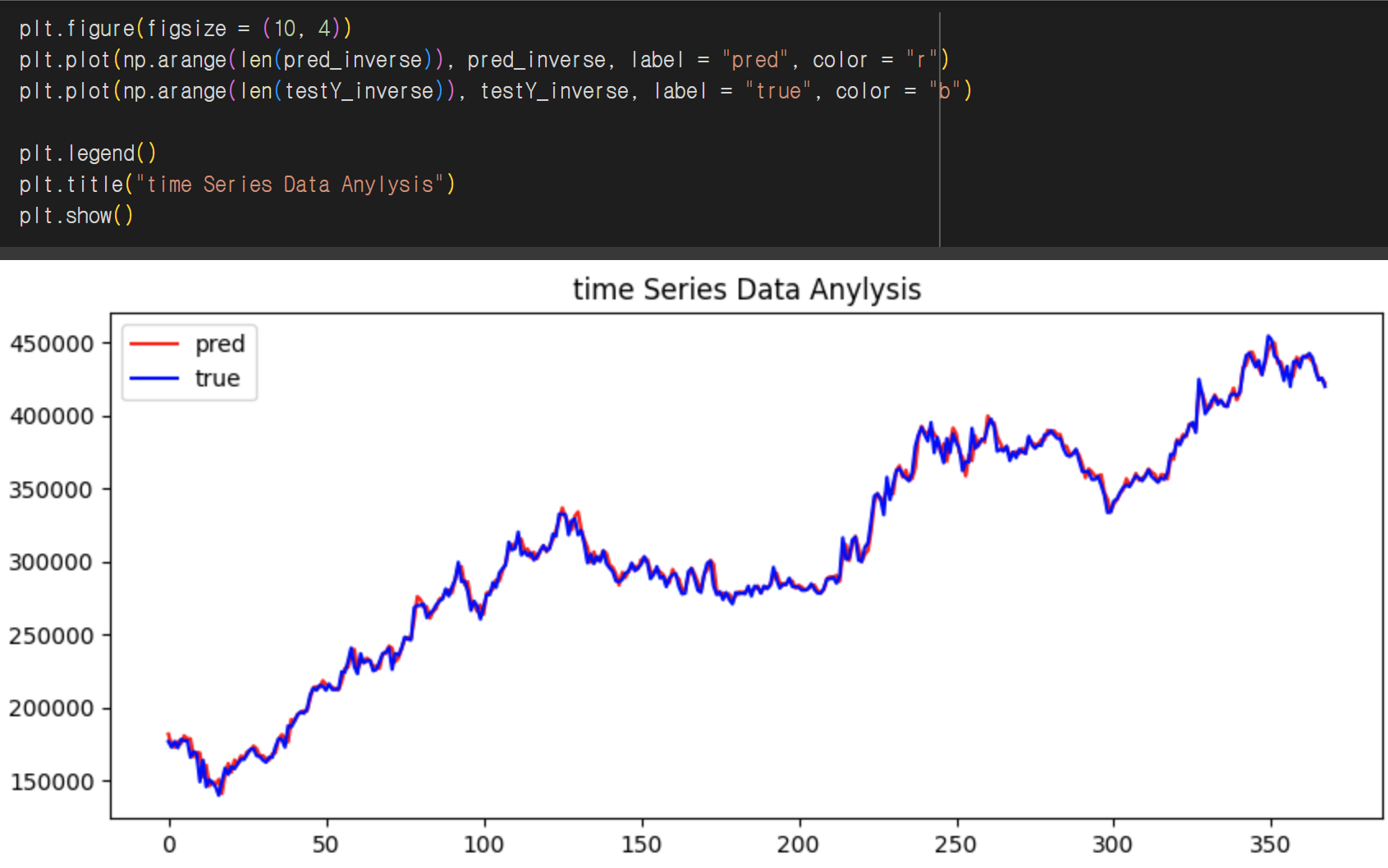
그럼 딥러닝 모델로 어떤 것을 할 수 있을까?
딥러닝 모델을 만드는 실습을 진행하고 다음 단계로는 이 딥러닝 모델을 활용한 서비스인 openCV 및 Mediapipe 실습해 보는 시간을 가졌다. Mediapipe는 구글에서 만든 멀티모달 AI 프레임워크로 실시간으로 얼굴이나 손, 몸의 움직임을 감지하고 추적하는 기능을 제공해 준다.
Mediapipe를 활용해 손 관절 포인트를 추적하는 Hand Landmark 모델을 사용해, 가위, 바위, 보 모양을 실시간으로 감지하는 기능을 만들어 봤다. 각 손 모양에 대한 사진을 직접 찍어서 모델에 학습시키고 실시간으로 손 모양을 바꿀 때마다 어떤 모양인지 출력되도록 만들었다.

이 실습을 통해서 내가 직접 만든 데이터와 기능으로 실제 결과가 나오는 경험을 해볼 수 있었고, 출력값을 보면서도 “이 딥러닝 모델은 어떤 데이터를 바탕으로 학습된 결과일까?”라는 거꾸로의 관점도 자연스럽게 생기게 되었다.
딥러닝에 대한 필요한 개념과 원리 그리고 실습하는 시간을 통해서 '이걸 어디에 활용할 수 있을까?'라는 물음이 나에게는 조금 더 중요한 관점이라는 것을 알게 된 시간이었다. 다음 편에서는 딥러닝 파트에서 진행했던 프로젝트에 대한 회고를 기록해 보려고 한다.
next is "최애야, 오늘 뉴스 읽어줘 ♥️"
'원티드 포텐업 부트캠프 기록' 카테고리의 다른 글
| [비전공자의 AI 부트캠프 일지 #10] 딥러닝 프로젝트 회고 (1) | 2025.04.13 |
|---|---|
| [비전공자의 AI 부트캠프 일지 #8] 딥러닝 기초 개념 이해하기 (0) | 2025.03.30 |
| [비전공자의 AI 부트캠프 일지 #7] 머신러닝 프로젝트 회고 (0) | 2025.03.23 |
| [비전공자의 AI 부트캠프 일지 #6] 머신러닝 기초 정리_원티드 포텐업 부트캠프 (0) | 2025.03.02 |
| [비전공자의 AI 부트캠프 일지 #5] part2 .ML(머신러닝) 시작_원티드 포텐업 부트캠프 (2) | 2025.02.23 |